Categories
Archives

At the IPTC Autumn Meeting in Toronto in 2018, IPTC considered the issues of “trust and credibility” in news media. We looked at the existing initiatives and considered whether IPTC could contribute to the space.
We concluded that some existing efforts were doing great work and that we should not create our own trust and credibility standard. Instead, our resources could best be put towards working with those groups, and aligning IPTC’s standards — particularly our main news standards NewsML-G2 and ninjs — to work well with the outputs of those groups.
Since that time, the IPTC NewsML-G2 Working Group has been collaborating with several initiatives around trust and misinformation in the news industry. We have been working mainly with The Trust Project and the Journalism Trust Initiative from Reporters Without Borders, but have also been in communication with the Credibility Coalition, the Certified Content Coalition and others to identify all known means of expressing trust in news content.
Our aim is to make it easy for users of NewsML-G2 and ninjs to work with these standards to convey the trustworthiness of their content. This should make it easier for news publishers to translate trust information to something that can be read by aggregator platforms and user tools.
In particular, we want to make it as easy as possible for syndicated content to be distributed and published in alignment with trust principles.
A new IPTC Guideline document
To that end, we are publishing a “public draft” of a new IPTC guideline document: Expressing Trust and Credibility Information in IPTC Standards. While not complete, we hope that it helps IPTC members and other users of our standards to understand how they can express trust indicators.
To go along with the draft, we are proposing some changes to existing IPTC standards, including updates to NewsML-G2 and to ninjs, and a new Trust Indicator taxonomy created as part of the IPTC NewsCodes.
New Genres in NewsCodes and changes to NewsML-G2 and ninjs
To accommodate the new work, we will be adding some new entries to the NewsCodes Genre vocabulary. Some genres required for this work such as “Opinion” and “Special Report” were already in the genres vocabulary, but we are proposing to add new genres including “Fact Check” and “Satire“, and some genres to handle sponsored content: Advertiser Supplied, Sponsored and Supported.
We will also be making some small changes to the existing ninjs and NewsML-G2 standards to accommodate some new requirements, such as being able to associate a publisher with another organisation, to indicate membership of The Trust Project, Journalism Trust Initiative or a similar group.
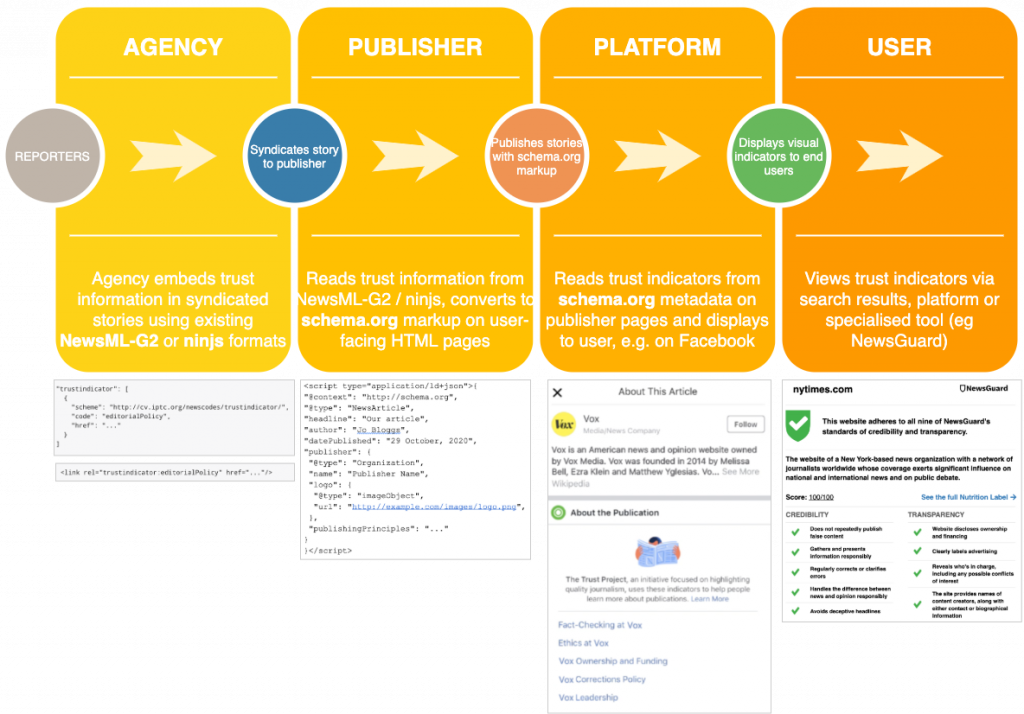
From trusted agency to publisher and then to a user
By following the guidelines, a news agency can add their own trust information to the news items that they distribute. A publisher can then take those trust indicators and convert them to the standard schema.org markup used to convey trust indicators in HTML pages (initially created via a collaboration between schema.org and The Trust Project in 2017).
The schema.org markup can then be read by search engines, platforms such as Facebook, and specialised trust tools such as the NewsGuard browser plugin, so that users can see the trust indicators and decide for themselves whether they can trust a piece of news.
Please give us your feedback
The document will not be final until after those changes have been approved by IPTC members at our next meeting in May.
We have published the draft to ask for feedback from the community about how we could improve our guidance, ask for any trust indicators that we have missed, and to ask for implementation feedback.
Please use the IPTC Contact Us form to send your feedback.
About the Trust Project
The Trust Project is a global network of news organizations working to affirm and amplify journalism’s commitment to transparency, accuracy and inclusion. The project created the Trust Indicators, which are a collaborative, journalism-generated standard for news that helps both regular people and the technology companies’ machines easily assess the authority and integrity of news. The Trust Indicators are based in robust user-centered design research and respond to public needs and wants.
For more information, visit thetrustproject.org.
The Trust Project is funded by Craig Newmark Philanthropies, Democracy Fund, Facebook, Google and the John S. and James L. Knight Foundation.
About the Journalism Trust Initiative
The Journalism Trust Initiative aims at a healthier information space. It is developing indicators for trustworthiness of journalism and thus, promote and reward compliance with professional norms and ethics. JTI is led by Reporters Without Borders (RSF) in partnership with the European Broadcasting Union (EBU), the Global Editors Network (GEN) and Agence France Presse (AFP).
For more, visit https://jti-rsf.org/en/
 In late February we pushed the latest update to Media Topics, IPTC’s main controlled vocabulary for subject classification (also known as a taxonomy).
In late February we pushed the latest update to Media Topics, IPTC’s main controlled vocabulary for subject classification (also known as a taxonomy).
This release includes a translation of NewsCodes into the Danish language.
On behalf of the NewsCodes Working Group and its chair Jennifer Parruci, we would like to say thanks very much to Mette-Lene Østergaard and Mads Petersen from the Danish news agency Ritzau in Denmark for all their work on making the translation.
It’s available from all the usual places:
- The main IPTC Controlled Vocabulary server at cv.iptc.org, which includes both human- and machine-readable versions of all IPTC NewsCodes: http://cv.iptc.org/newscodes/mediatopic/
- HTML browsable view: https://www.iptc.org/std/NewsCodes/mediatopic/treeview/
- Graphical tree view: http://show.newscodes.org/index.html?newscodes=medtop&lang=dk&startTo=Show
- Downloadable Excel version: https://www.iptc.org/std/NewsCodes/IPTC-MediaTopic-NewsCodes.xlsx
The IPTC Media Topic NewsCodes vocabulary is now available in 9 languages: Arabic, British English, Danish, French, German, Portuguese, Brazilian Portuguese, Spanish and Swedish.
We are working with partners on several more language translations coming very soon. If you would like to work with us on contributing a new language translation of IPTC Media Topics or any other IPTC standard, please contact us!
We were very much looking forward to our IPTC 2020 Spring Meeting in Tallinn, Estonia, beautiful city on the Baltic Sea and home city of Brendan Quinn, Managing Director of IPTC. But unfortunately, circumstances mean that we can not hold the meeting in person this time.
Instead we are looking forward to hosting IPTC’s first ever virtual Spring Meeting!
We will be going ahead with the dates that we had planned: Monday May 11 to Wednesday May 13, but rather than having all-day sessions, we will be having sessions from 13.00 to 18.00 UTC on each day.
This meeting will include:
- The usual updates from our working groups including the Photo Metadata Working Group, Video Metadata Working Group, News Architecture Working Group, NewsCodes Working Group, News in JSON Working Group, Sports Content Working Group
- Speakers from IPTC Members such as Reuters, New York Times, Bloomberg and TT on related projects in their newsrooms
- Invited guest speakers from companies related to our standards and key topics
- The special topic focus for this meeting is “robojournalism” and automated media generation
- Because we know how attendees love the networking and interaction sides of our face-to-face meetings, we will have several sessions that aim to let attendees discuss issues with each other and encourage participation in side rooms and through other channels such as our Slack community.
All IPTC Members are invited to attend. For this virtual meeting, there is no cost for IPTC members to attend.
IPTC Member Delegates should look out for an email from Brendan Quinn containing the registration link, or see the event page on the IPTC Members-Only Zone for the registration link.
We are pleased to announce that we have updated our popular Quick Guide to IPTC Photo Metadata and Google Images document to cover the planned updates to Google Image search that we announced last week.
First published in October 2018 after the announcement that Google Images displays image credits based on embedded IPTC Photo Metadata, the Quick Guide has proved very popular as a quick instruction guide showing how photographers and image owners can add the correct metadata fields to their images in a way that ensures image rights information will be displayed in Google search results pages.
Now that Google’s updates to handle “licensable images” have been announced (in beta), we have added new sections to the document so everyone can see all of the IPTC Photo Metadata fields used by Google in one place. We also make clear which fields will be used by Google straight away and which fields will only be displayed after the public launch of the new feature.
All comments and suggestions to the document are welcome. Please post to the public iptc-photometadata discussion list or use the IPTC contact form if you would like to get in touch.
We are excited to announce that the result of our latest collaboration with Google has been launched in a beta phase: Licensable Images.
This feature, that Google is exploring with this beta, will enable image owners not only to receive credit for their work but also to find ways to raise people’s awareness of licensing requirements for content found via Google Images.
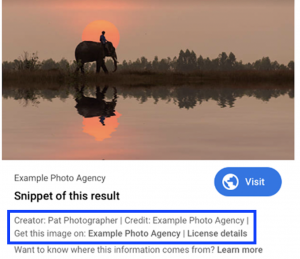
By embedding IPTC Photo Metadata fields into their images (or using schema.org markup), Google will place a badge on licensable images in search results pages.
Under the image preview, Google will show embedded rights metadata (creator, copyright and credit fields). These have been displayed since IPTC’s collaboration with Google in 2018, but will now be given more prominence.
Along with the rights metadata, Google will now show links to the image’s usage licence and also a link to “Get this image”.
See the image for a mockup of how it might look.
By embedding IPTC Photo Metadata into your images, these links will be shown for images on your own website and also when your customers publish images on their sites.
Along with the photo industry organisation CEPIC, IPTC has been working with Google on this project since the IPTC Photo Metadata Conference at CEPIC Congress in June 2019.
The user-facing side of the feature is planned to launch in the next few months. Google has released some developer documentation to encourage image owners to get ready for the launch.
Learn how to make licensable images work for your image collections
For IPTC members, we will be running a webinar today, Thursday 20 February at 15:00 GMT.
The webinar will explain how the licensable images feature works and what image owners can do to get ready for the launch.
The speakers will be Michael Steidl, Lead of the IPTC Photo Metadata Working Group, and Brendan Quinn, Managing Director of IPTC.
Please check your email for the announcement and information on how to join.
For non-members, we will be publishing a page on this site on Friday 21 February that will explain how to take advantage of the feature.
UPDATE: We have now updated our Quick Guide to IPTC Photo Metadata and Google Images to include information on how to embed rights and licensing metadata in your images.
We’re very pleased to see this launch. We look forward to seeing how our members will use this feature to draw more attention to the importance of image rights and licensing.
To support the work of IPTC in this and other areas, please consider joining IPTC.
Following many change requests submitted by news organisations all over the world, the IPTC News in JSON Working Group is happy to announce the 1.2 version of its standard ninjs.
The JSON Schema of the new version can be accessed at https://www.iptc.org/std/ninjs/.
We also created a ninjs User Guide that will enable new and existing users to understand how to put ninjs to use at their organisation.
Version 1.2 is backwards-compatible with version 1.0 and 1.1 and makes no breaking changes.
It includes the following new properties and structures:
- The
firstcreatedproperty goes along with theversioncreatedproperty to specify the date/time when the first version of a news item was published. - The
charcountandwordcountproperties allow the publisher to specify the total character count and word count of a news item (excluding figure captions and metadata). - The
slugline, property allows the publisher to specify a “slug”, a human-readable identifier for the item. (note that no conditions are placed on the usage of this property, usage is up to each publisher). - The
ednote, property allows publishers to specify instructions to editors. - The
infosourcestructure can specify one or many information sources for the news item. It is a metadata structure that can handle literal strings or values from a controlled vocabulary. - The
titleproperty handles “A short natural-language name for the item.”
Also the following sub-properties were added:
- The value
componentwas added to the allowed values fortypeto specify parts of a larger news item. - The description of the
renditionsproperty was changed to allow for any type of rendition, not just images, and new sub-propertiesdurationandformatwere added to enable audio and video renditions (for example, an audio version of a text story).
We have also included a test and validation suite so new versions of the JSON Schema can automatically be checked for compliance and backwards compatibility.
ninjs 1.2 is now included in the SchemaStore.org JSON Schema repository, to aid with editing and validation of ninjs 1.2 files in a range of popular code editors such as Visual Studio Code and Visual Studio 2013+, IntelliJ IDEA, PyCharm and PHPStorm.
For more information, please see:
- The ninjs GitHub repository
- ninjs example documents
- The ninjs User Guide
- The ninjs 1.2 JSON Schema specification
- A new interactive tool for creating example ninjs documents – the ninjs Generator
If you have any questions or comments, please contact the News in JSON Working Group via the public ninjs discussion group, or contact IPTC via the Contact Us form.
IPTC is pleased to release a new version of its widely used Photo Metadata Standard, version 2019.1. This version introduces the exciting new feature to mark regions within an image using embedded metadata, directly in the image file.
Any existing or future IPTC Photo Metadata field can now be attached either to the image as a whole, or to an IPTC Image Region defined within the image.
“IPTC has received many requests from photographers and photo businesses for enabling them to set a region inside an image and to apply specific metadata to it, with the new version of the standard this can be done,” said Michael Steidl, Lead of the IPTC Photo Metadata Working Group. “We hope IPTC Image Regions will be supported by imaging software soon.”
What can IPTC Image Regions be used for?
IPTC Image Regions can be used for many purposes:
- An IPTC Image Region can be used to recommending an area of particular interest in an image to be retained after cropping.
- A photographer or picture editor can use IPTC Image Regions to specify the area to be used if a crop of a different shape is required, such as a square cropping in a landscape shot.
- An IPTC Image Region can frame people in an image, using associated metadata from other fields in the standard attached to only that region, such as Person Shown. This opens up the possibility of news stories avoiding tired “from left to right: Jo Smith, Bill Jones, Susan Bloggs…” image captions. Now we have the ability to embed the names and details of people directly on the region relating to that person, so tools could display people’s names when a user’s pointer hovers over their faces.
- IPTC Image Regions can be used to highlight products, artworks, or locations depicted within an image.
- Another attractive feature of image regions is to identify the copyright owners of multiple photos integrated into a single composite image.
- AI systems identifying objects, text, products and people in images no longer have to include the region information in sidecar files distributed with images. Using IPTC Image Regions, the information can be embedded within the image file itself.
There are many more possible use cases. We are looking forward to seeing applications of IPTC Image Regions that we haven’t even thought of!
What shapes are supported?
According to the Specification, an IPTC Image Region can take the shape of a rectangle, a circle or for more complicated shapes, a polygon with any number of vertices may be used.
Dimensions of image regions can be specified in absolute (pixels) or relative (percentage) formats, and the Specification describes how software should retain IPTC Image Region information so that it is still meaningful after the image is cropped or transformed.
Image types and roles
To help with depicting different types of information using IPTC Image Regions, we have created two fields: Image Region Type and Image Region Role.
- Image Region Type asserts the type of content of the region, denoting whether the image region shows a person, animal, bar code, product etc.
- Image Region Role asserts what the region is used for. Examples might be to specify a recommended cropping area, a sub-image inside a composite image, the main subject to be used for cropping and focus purposes, or a region with special copyright information.
We have created controlled vocabularies that can optionally be used to populate both of these fields and we maintain them as part of the IPTC NewsCodes: Image Region Type and Image Region Role. The IPTC NewsCodes Working Group and Photo Metadata Working Groups may add terms to these vocabularies over time.
What metadata can be added to an IPTC Image Region?
In addition to Image Region Type and Role, any of the existing IPTC Photo Metadata fields can be used to describe an IPTC Image Region. Examples of fields that may be useful to attach to a region are:
- Persons Shown (for name only)
- Person Shown with Details (which supports name and also identifier such as a Wikidata or IMDB ID, controlled vocabulary entries and description)
- Organisations Featured
- Product Shown
- Artwork or Object Shown
- Location Shown (for example, a photograph of a mountain range taken from a distance)
This well organised structure of information about a region in an image can also help software makers to show the boundary of regions and associated metadata at the click of a button.
Help for users and for implementers
Users interested in exploring how IPTC Image Regions can be used can find more in a section about it in the IPTC Photo Metadata User Guide. Some examples are already available showing how an image with regions looks and how they can depict different types of information.
For implementers wanting to support IPTC Image Regions in their software tools, all definitions of the Image Region can be found in the IPTC Photo Metadata Standard specification document. The Specification includes detailed information show to express an image boundary correctly and how to include deliberately used metadata fields describing the content of a region.
Software support
Thanks to Phil Harvey, exiftool has supported IPTC Image Regions since version 11.74. The full source plus Windows and Mac OS packages can be downloaded from https://exiftool.org/.The CPAN version of exiftool does not yet support IPTC Image Regions.
We will link to other software supporting IPTC Image Regions as they become available.
Interested in more information?
- The full specification for IPTC Photo Metadata Standard 2019.1 including IPTC Image regions is available from https://www.iptc.org/std/photometadata/specification/IPTC-PhotoMetadata
- A more user-friendly Photo Metadata User Guidelines can be accessed at https://www.iptc.org/std/photometadata/documentation/userguide/
- See a demo using some example files with marked regions at https://www.iptc.org/std/photometadata/examples/image-region-examples/
- The controlled vocabularies for Image Region Type and Image Region Role can be accessed as part of the IPTC NewsCodes.
Questions, comments, ideas?
We welcome your ideas, thoughts and especially implementations!
Please get in touch via the contact form on this site.
At the IPTC Meeting in Ljubljana Slovenia in Autumn 2019, we welcomed several new faces to IPTC working groups, the Board and voted in a new Chair!
With so many changes happening at the same time, we thought it would be good to introduce the new faces here so members and others can get to know them all better. (All IPTC working group leads, committee leads and directors can be found on the Work Structure and About IPTC pages.)
Video Metadata Working Group lead: Pam Fisher
 Pam Fisher is with IPTC as an Individual Member, and we are very happy to have her lead the Video Metadata Working Group, looking at further development and promotion of Video Metadata Hub and video technology in general.
Pam Fisher is with IPTC as an Individual Member, and we are very happy to have her lead the Video Metadata Working Group, looking at further development and promotion of Video Metadata Hub and video technology in general.
Pam has a long history with media and video technology, working with organisations such as BAFTA, Moving Image Research and Communication Arts.
News in JSON Working Group lead: Johan Lindgren
 Johan has led the Sports Content Working Group since 2016 but with the current resurgence of interest in JSON news formats, decided to move to lead the News in JSON Working Group.
Johan has led the Sports Content Working Group since 2016 but with the current resurgence of interest in JSON news formats, decided to move to lead the News in JSON Working Group.
Representing TT Nyhetsbyrån, Sweden’s national news agency, Johan has been active with IPTC for over 20 years, a regular meeting attendee and has been on the IPTC Board since 2016.
Sports Content Working Group lead: Paul Kelly
With Johan taking the reins of the News in JSON group, Paul is stepping (back) up to lead the Sports Content working group. Paul is also a long-time IPTC member, having been lead of the Sports Content working group from 2005 through to 2016 while he represented XML Team Solutions. Now an independent consultant, Paul has retained his ties with IPTC as an Individual Member and we are very happy to see him leading the Sports Content working group once more.
Chair of the IPTC PR Committee: Linda Burman
Linda has been an Individual Member since 2015, and has actively participated in several working groups including the Photo Metadata and Video Metadata Working Groups. We look forward to reviving the IPTC Public Relations Committee under Linda, looking at how to spread the word about the benefits of IPTC to the media industry and beyond.
New Board member: Jennifer Parrucci
 Jennifer has been an IPTC delegate for the New York Times since 2015, and lead of the News Codes Working Group since 2016. Jennifer has done a great job in leading the News Codes Working Group to maintain and develop the News Codes taxonomies, particularly the Media Topics subject vocabulary. We are looking forward to Jennifer’s contributions to the future of IPTC as part of the Board.
Jennifer has been an IPTC delegate for the New York Times since 2015, and lead of the News Codes Working Group since 2016. Jennifer has done a great job in leading the News Codes Working Group to maintain and develop the News Codes taxonomies, particularly the Media Topics subject vocabulary. We are looking forward to Jennifer’s contributions to the future of IPTC as part of the Board.
New Board member: Paul Harman
 Paul Harman has been an IPTC member for over 20 years, first with Press Association and now with Bloomberg LP. Paul worked on NewsML 1, NewsML-G2 and News in JSON (ninjs) while he was an architect with Press Association and carried it on at Bloomberg, his employer since 2014.
Paul Harman has been an IPTC member for over 20 years, first with Press Association and now with Bloomberg LP. Paul worked on NewsML 1, NewsML-G2 and News in JSON (ninjs) while he was an architect with Press Association and carried it on at Bloomberg, his employer since 2014.
Paul is an active member of the News Architecture, News in JSON and News Codes working groups, and we’re very happy to welcome him to the IPTC Board of Directors.
New Chair: Robert Schmidt-Nia
 Robert has been with IPTC since 2007 representing dpa, the German national news agency, where he has been Managing Director of subsidiary dpa mediatechnology since 2013.
Robert has been with IPTC since 2007 representing dpa, the German national news agency, where he has been Managing Director of subsidiary dpa mediatechnology since 2013.
Robert joined the board of IPTC in 2013 and has been a very active participant, so we were very happy to see him voted by the membership to become Chair of the IPTC Board of Directors.
Welcome to everyone and thanks for sharing your time, knowledge and expertise. Your fellow members appreciate it!
This is part of a series of posts about the IPTC Autumn Meeting 2019. In Ljubljana. See separate posts about Day 1 and Day 2.
Day 3 of the Ljubljana Meeting was where we got down to business: we hosted the 2019 IPTC Annual General Meeting, where Voting Members get to have their say on how the organisation is run, voting on the budget and the Board.
We are very happy to announce that Jennifer Parrucci of the New York Times and Paul Harman of Bloomberg were both voted as new IPTC Board members and Directors of the company, and that Robert Schmidt-Nia of DPA was voted as Chair of the IPTC Board.
On behalf of all IPTC members we would like to say thanks, and welcome!
Then we had the IPTC Standards Committee meeting where we approved the latest versions of two of our key standards: IPTC Photo Metadata Standard 2019.1 and ninjs 1.2. Stay tuned for more information on both of those very soon!
In the afternoon we had a visit to the Triglav Lab where we were able to see some interesting developments in the Slovenian tech scene related to media. Thanks again to Aljoša Rehar from STA and Marko Grobelnik from Jožef Stefan Institute for their help in organising the afternoon.
We heard from:
- Event Registry , a “news intelligence platform” that semantically tags content to identify meaning and disambiguate between potential meanings for the same words, allowing for cross-language tagging and clustering to create “news events” across articles in multiple languages
- Embeddia, a JSI project in partnership with STT Finland and Ekspress meedia in Estonia, looking at using structured data to create “intelligence augmentation”, as opposed to AI, helping journalists to do their jobs better. It also focuses on less-popular languages such as Slovene, Finnish and Estonian where some standard AI tools don’t work as well.
- Internal projects at STA including an article tracker which allows the agency can track usage of their content, even if it is modified; a tool called D4 which allows STA to see which stories they have been missing and how they can find new stories; and Newsmapper which provides analytics about STA’s own content – where was it popular? with what types of readers?
- Behaviour Exchange, a user analytics tracker that allows publishers to understand their users’ demographics and preferences, including their own ad network, rather than outsourcing their user analytics to the big platforms.
- A representative from Blockchain Think Tank Slovenia spoke about media implications of blockchain and what it could do for the media industry.
- Finspektor showed how they are used open data to analyse how the Slovenian government is spending their taxpayers’ money
- and Parlameter showed how they are bringing politicians to account, showing their activity in parliament, on social media and in the media.

It was a great way to end a fascinating three day event!
And on the Thursday some of us were able to go on a networking day to Postojna Cave where we were able to see the beautiful tunnels and some very impressive underground. Some of us were also able to go on to the stunning Lake Bled, which we definitely would recommend!
Thanks again to Aljoša, Nejc, Marjana, Marko and the team from STA and JSI for helping to organise the event.
Day 2 of the IPTC Autumn Meeting 2019 was just as busy as Day 1: we heard from the IPTC NewsCodes Working Group, the AI Expert Group, and the News Architecture Working Group including updates on IPTC’s work on trust and credibility projects. We also had updates from the Video Metadata Working Group, an update on IPTC’s Rights work, and news from the Sports Content Working Group. Phew!
Jennifer Parrucci from the New York Times, lead of the IPTC NewsCodes Working Group, introduced IPTC NewsCodes and discussed recent progress, including cleaning up large parts of the Media Topics vocabulary. The Working Group also announced new language translations coming very soon: Portuguese and Brazilian Portuguese are ready, Chinese is almost ready, and some other language versions are in progress.
We also had an interesting and productive discussion about the workflow and process around Media Topics translations. As the team adds and retires terms and definitions, how should translations be managed? Should we not publish changes until we have translations in all languages? Or should there be a core of languages that require translations? Should we publish interim versions with un-synced changes and less frequent “stable” versions of Media Topics including all translations? We are having success using GitHub issues to manage regular changes to the taxonomy: can technology also help in managing the translation process and if so, which tools? Many ideas and thoughts were shared, including the perspectives of many member organisations who already work across multiple languages.

Tao Chen, VP of Machine Learning at 500px and lead of the new AI Expert Group, gave a great overview of the latest developments in AI affecting the media industry. From practical developments, like removing backgrounds from stock images, detecting copyright infringement and assessing the commercial potential of images, to the dangers of face swapping apps and a potential future of completely generated images that feature no real human beings, we learned a lot about how AI affects us today and tomorrow. We are building up the AI Expert Group to become the place where media technologists can go to learn the latest on AI and Machine Learning issues, apply the latest techniques in the media industry, and share ideas with their peers. If you’re a member and not yet involved, please talk to Tao or Brendan to get started.
Next up, Brendan Quinn spoke about IPTC’s recent work with the Journalism Trust Initiative and The Trust Project, on mapping their “trust indicators” to IPTC standards (particularly NewsML-G2) so news providers can show how they comply with trust criteria. Look out for some announcements about this work in the next few weeks. Then Dave Compton of Refinitiv, lead of the News Architecture Working Group gave an update on recent work on NewsML-G2, including the trust and credibility work, a NewsML-G2 2.28 errata release fixing some small typo errors, updates to the NewsML-G2 Guidelines and the NewsML-G2 Specification documents, work on making local extensions to Media Topics, and future work, including looking at how to represent auto-generated content, and better alignment with ninjs (see Monday’s wrap-up post for more on our recent ninjs updates).

After lunch, Pam Fisher of The Media Institute at University College London spoke about her project to build a read/write API that maps metadata between various video formats. We will link to a demo as soon as it is available. Pam also discussed “compact video signatures”, part of MPEG7, which are being used to make content fingerprints for video content, used for infringement detection and content matching.
Pam’s talk was very relevant to the next discussion by Michael Steidl, lead of the Video Metadata Working Group updating on recent progress. The Working Group has been looking at new video APIs and understanding how IPTC members and others are using video metadata in their work, either with or without IPTC Video Metadata Hub.
In the afternoon Michael Steidl presented again with an update on his work with W3C’s ODRL group which impacts on RightsML. Johan Lindgren presented in lieu of Paul Kelly, new Lead of the Sports Content Working Group, giving an update on the Working Groups efforts to interview IPTC members and others about their use of sports data and to position SportsML and our work on SportsJS in the context of the news and media industry.

Finally we bade farewell to Stuart Myles, outgoing Chair of IPTC. We presented Stuart with a small token of our thanks for chairing the Board of Directors of IPTC since 2014, and has been involved with IPTC as a delegate since 1999! We will definitely miss his contributions, intelligence, common sense and enthusiasm, and we hope to see him involved with IPTC again in the future in some way.