Categories
Archives
Earlier this year, we announced the arrival of Brendan Quinn, the new managing director of the International Press Telecommunications Council.
And while we’re thrilled to welcome Brendan to his new role, we’d be remiss if we didn’t take a moment to honour the man whom he’ll be replacing: Michael Steidl, who is retiring from the IPTC after 15 years.
Michael joined IPTC in the beginning of 2003 after two decades working as a journalist, managing director for news agencies and information technology consultant for news providers.
Upon his arrival, he pledged to do one thing, recalled IPTC Board Chairman Stuart Myles in a tribute at the recent IPTC Spring Meeting 2018.
Michael didn’t want to reinvent the wheel, but to simply continue the good work of the previous director and “add some extra shades of colour” to IPTC’s image as a leader in news industry standards.
Of course, Michael did more than just add a few extra shades. Myles said:
“In fact, I would say that Michael’s contributions to the IPTC is really more equivalent to an entirely new artistic movement – a sort of Renaissance for the organisation – including managing the introduction of entirely new ways of operating the IPTC. When Michael started, there were no teleconferences or video conferences or even development of standards through email lists. There was no internet available during the meetings – which has perhaps been a mixed blessing, since people can keep up with the work back home, but we aren’t always as focussed.”
Klaus Sprick, a former IPTC board member who has been involved with the organisation for nearly 50 years, said the council – and the industry as a whole – owes Michael a debt.
“He is THE key person in IPTC to have moved it forward,” Sprick said. “IPTC is now, thanks to his efforts, the only respected and acknowledged organisation setting standards in international press information technology: media topics, subject codes, metadata, formats.”
Michael has called his time with the IPTC a great experience, adding he was happy to have been involved with the development and launch of nine new standards, the new Media Topic taxonomy and other vocabularies, and in his role in setting up new formats for face-to-face meetings and the creation of new kinds of meetings.
“Being in contact with our membership is also part of the bright side of my IPTC life and I enjoyed spreading the word about IPTC and its work among people knowing only little or nothing about our organisation.”
Prior to joining IPTC, Michael spent 11 years as managing director of Kathpress, where he had also worked as journalist. He has also worked as vice press officer for Medienstelle ED Wien, and as a freelance reporter for ORF.
We wish Michael a very happy retirement and thank him once again for the work he’s done to bring the IPTC to where it is today.
The International Press Telecommunications Council is happy to announce that RightsML, IPTC’s Rights Expression Language for the media industry, has been updated to version 2.0.
RightsML allows publishers and media owners to express rights permissions and obligations based on geographic, time-based, and monetary restrictions.
This version contains major updates: it is now based on W3C’s Open Digital Rights Language (ODRL) version 2.2 which became a W3C recommendation in February 2018.
ODRL allows content providers to “express permission, prohibition, and obligation statements to be associated to content.” RightsML extends on that base to provide standard expressions for geographic and time-based constraints, on a requirement to pay fixed amounts of money for use of the content,
An example RightsML model which expresses that EPA (Example Press Agency) grants its partners geographic rights to distribute a content item in Germany is as follows:
Policy: type: "http://www.w3.org/ns/odrl/2/Set" uid: "http://example.com/RightsML/policy/idGeog1" profile: "https://iptc.org/std/RightsML/odrl-profile/" permission: - target: "urn:newsml:example.com:20120101:180106-999-000013" assigner: "http://example.com/cv/party/epa" assignee: type: "http://www.w3.org/ns/odrl/2/PartyCollection" uid: "http://example.com/cv/partygroup/epapartners" action: "http://www.w3.org/ns/odrl/2/distribute" constraint: - leftOperand: "http://www.w3.org/ns/odrl/2/spatial" operator: "http://www.w3.org/ns/odrl/2/eq" rightOperand: "http://cvx.iptc.org/iso3166-1a3/DEU"
This content model can also be expressed in XML or JSON. See the RightsML Simple geographic Example for more information.
More examples are on the RightsML 2.0 Examples page on the IPTC developer site.
IPTC has also created tools to help implementors understand and implement RightsML 2.0, including a generic guideline flow for evaluating ODRL documents and a RightsML policy builder tool.
For more details and help on implementing RightsML within your organisation, please join the IPTC RightsML mailing list. Membership of the group is open to the public. For discussion on developing further versions of the standard, please use the IPTC RightsML-dev list, open to all IPTC members.
… the image business in a changing environment
By Sarah Saunders
The web is a Wild West environment for images, with unauthorised uses on a massive scale, and a perception by many users that copyright is no longer relevant. So what is a Smart Photo in this environment? The IPTC Photo Metadata Conference 2018 addressed the challenges for the photo industry and looked at some of the solutions.
Isabel Doran, Chair of UK image Library association BAPLA kicked off the conference with some hard facts. The use of images – our images – has created multibillion dollar industries for social media platforms and search engines, while revenues for the creative industry are diminishing in an alarming way. It has long been been said that creators are the last to benefit from use of their work; the reality now is that creators and their agents are in danger of being squeezed out altogether.
Take this real example of image use: An image library licenses an image of a home interior to a company for use on their website. The image is right-click downloaded from the company’s site, and uploaded to a social media platform. From there it is picked up by a commercial blog which licenses the image to a US real estate newsfeed – without permission. Businesses make money from online advertising, but the image library and photographer receive nothing. The image is not credited and there is no link to the site that licensed the image legitimately, or to the supplier agency, or to the photographer.
Social media platforms encourage sharing and deep linking (where an image is shown through a link back to the social media platform where the image is posted, so is not strictly copied). Many users believe they can use images found on the web for free in any way they choose. The link to the creator is lost, and infringements, where found, are hard to pursue with social media platforms.
Tracking and enforcement – a challenge
The standard procedure for tracking and enforcement involves upload of images to the site of a service provider, which maintains a ‘registry’ of identified images (often using invisible watermarks) and runs automated matches to images on the web to identify unauthorised uses. After licensed images have been identified, the image provider has to decide how to enforce their rights for unauthorised uses in what can only be called a hostile environment. How can the tracking and copyright enforcement processes be made affordable for challenged image businesses, and who is responsible for the cost?
The Copyright Hub was created by the UK Government and now creates enabling technologies to protect Copyright and encourage easier content licensing in the digital environment. Caroline Boyd from Copyright Hub demonstrated the use of the Hub copyright icon for online images. Using the icon (like this one ![]() ) promotes copyright awareness, and the user can click on the icon for more information on image use and links back to the creator. Creating the icon involves adding a Hub Key to the image metadata. Abbie Enock, CEO of software company Capture and a board member of the Copyright Hub, showed how image management software can incorporate this process seamlessly into the workflow. The cost to the user should be minimal, depending on the software they are using.
) promotes copyright awareness, and the user can click on the icon for more information on image use and links back to the creator. Creating the icon involves adding a Hub Key to the image metadata. Abbie Enock, CEO of software company Capture and a board member of the Copyright Hub, showed how image management software can incorporate this process seamlessly into the workflow. The cost to the user should be minimal, depending on the software they are using.
Publishers can display the icon on images licensed for their web site, allowing users to find the creator without the involvement of – and risk to – the publisher.
Meanwhile, suppliers are working hard to create tracking and enforcement systems. We heard from Imatag, Copytrack, PIXRAY and Stockfood who produce solutions that include tracking and watermarking, legal enforcement and follow up.
Design follows devices
Images are increasingly viewed on phones and tablets as well as computers. Karl Csoknyay from Keystone-SDA spoke about responsive design and the challenges of designing interfaces for all environments. He argued that it is better to work from simple to complex, starting with design for the smartphone interface, and offering the same (simple) feature set for all environments.
Smart search engines and smart photos
Use of images in search engines was one of the big topics of the day, with Google running its own workshop as well as appearing in the IPTC afternoon workshop along with the French search engine QWANT.
Image search engines ‘scrape’ images from web sites for use in their image searches and display them in preview sizes. Sharing is encouraged, and original links are soon lost as images pass from one web site to the next.
CEPIC has been in discussion with Google for some time, and some improvements have been made, with general copyright notices more prominently placed, but there is still a way to go. The IPTC conference and Google workshop were useful, with comments from the floor stressing the damage done to photo businesses by use of images in search engines.
Attendees asked if IPTC metadata could be picked up and displayed by search engines. We at IPTC know the technology is possible; so the issue is one of will. Google appears to be taking the issue seriously. By their own admission, it is now in their interest to do so.
Google uses imagery to direct users to other non-image results, searching through images rather than for images. Users searching for ‘best Indian restaurant’ for example are more likely to be attracted to click through by sumptuous images than by dry text. Google wants to ‘drive high quality traffic to the web ecosystem’ and visual search plays an important part in that. Their aim is to operate in a ‘healthy image ecosystem’ which recognises the rights of creators. More dialogue is planned.
Search engines could drive the use of rights metadata
The fact that so few images on the web have embedded metadata (3% have copyright metadata according to a survey by Imatag) is sad but understandable. If search engines were to display the data, there is no doubt that creators and agents would press their software providers and customers to retain the data rather than stripping it, which again would encourage greater uptake. Professional photographers generally supply images with IPTC metadata; to strip or ignore copyright data of this kind is the greatest folly. Google, despite initial scepticism, has agreed to look at the possibilities offered by IPTC data, together with CEPIC and IPTC. That could represent a huge step forward for the industry.
As Isabel Doran pointed out, there is no one single solution which can stand on its own. For creators to benefit from their work, a network of affordable solutions needs to be built up; awareness of copyright needs support from governments and legal systems; social media platforms and search engines need to play their part in upholding rights.
Blueprints for the Smart Photo are out there; the Smart Photo will be easy to use and license, and will discourage freeloaders. Now’s the time to push for change.
By Jennifer Parrucci from IPTC member New York Times
The NewsCodes Working Group has been tirelessly working on a project to review the definitions of all terms in the MediaTopics vocabulary.
The motivation behind this work is feedback received from members using the vocabulary that some definitions are unclear, confusing or not grammatically correct. Additionally, some labels have also been found to be outdated or insensitive and have been changed.
Changing these definitions and labels is not meant to completely change the usage of the terms. Definition and label changes are meant to refine and clarify the usage.
While reviewing each definition the members of the working group have considered various factors, including whether the definition is clear, whether the definition uses the label to define itself (not very helpful) and whether there are typos or grammatical errors in the definition. Additionally, definitions were made more consistent and examples were added when possible.
Once these changes were made in English, the French, Spanish and German translations were also updated.
Currently, updates are available for three branches of Media Topics:
- arts, culture and entertainment
- weather
- conflict, war and peace
Updates can be viewed in cv format on cv.iptc.org or in the tree view on show.newscodes.org.
The working group plans to continue working on the definition review and periodically release more updates as they become available.
As announced in late April, Brendan Quinn is succeeding Michael Steidl in the position of Managing Director of IPTC in June 2018.
This change is happening right now: Brendan has taken over the responsibilities and actions of the Managing Director and Michael is available for giving advice to Brendan until the end of June.
From now on Brendan should be contacted as Managing Director. He uses the same email address that Michael used before: mdirector@iptc.org.
Note from Brendan
I’m really looking forward to working with all IPTC’s members and friends, and hope that I can make a real difference to the future of the news and media industry through my work with IPTC.
I aim to speak with as many of you as possible over the next weeks and months to find out what you as members like and don’t like about what IPTC is doing, but in the meantime, please feel free to email me via mdirector@iptc.org or find me on the members-only Slack group, and I would be happy to say hello and to hear your thoughts.
Michael and I sat down to hand over the role in early June so I now have a sense of the task before me, and I hope that I can follow up on his work but also bring a fresh energy to the organisation.
I would especially like to thank Michael for all his efforts over the last 15 years in making IPTC what it is today.
Best regards, and see you in Toronto in October if not before!
Brendan.
Note from Michael
It was a great experience to help Brendan diving into the IPTC universe with all its members and workstreams plus many contacts in the media industry. I wish you, Brendan, all the best for a great future at this organisation.
Dear all who showed interest in IPTC, it was a pleasure getting in touch with you and I hope I was able to respond in a way helping you to solve problems.
I was invited to continue as Lead of the Photo Metadata and Video Metadata Working Groups and I’m happy to take on responsibility for these workstreams. If you want to contact me from now on please use my own email address mwsteidl@newsit.biz
Best,
Michael
An updated version 2.27 of NewsML-G2 is available as Developer Release
- XML Schemas and the corresponding documentation are updated
Packages of version 2.27 files can be downloaded:
- All XML Schemas plus full documentation (about 60 MB) from https://www.iptc.org/std/NewsML-G2/NewsML-G2_2.27.zip
- The same without XML Schema documentation in HTML (about 3 MB) from https://www.iptc.org/std/NewsML-G2/NewsML-G2_2.27-noXMLdocu.zip
- From the newsml-g2 repository on GitHub as a Release: https://github.com/iptc/newsml-g2
All changes of version 2.27 can be found on that page: http://dev.iptc.org/G2-Approved-Changes
The NewsML-G2 Implementation Guidelines are a web document now at https://www.iptc.org/std/NewsML-G2/guidelines
Reminder of an important decision taken for version 2.25 and applying also to version 2.27: the Core Conformance Level will not be developed any further as all recent Change Requests were in fact aiming at features of the Power Conformance Level, changes of the Core Level were only a side effect.
The Core Conformance Level specifications of version 2.24 will stay available and valid, find them at http://dev.iptc.org/G2-Standards#CCLspecs
The new Video Metadata Hub Recommendation 1.2 supports videos as delivered by professional video cameras by mapping their key properties to the common properties of the VMHub – see https://iptc.org/std/videometadatahub/mapping/1.2 – the new mappings are shown in columns at the right end of the table.
IPTC developed the Video Metadata Hub as common ground for metadata across already existing video formats with their own specific metadata properties. The VMHub is comprised of a single set of video metadata properties, which can be expressed by multiple technical standards, in full as reference implementation in XMP, EBU Core and JSON. These properties can be used for describing the visible and audible content, rights data, administrative details and technical characteristics of a video.
The Recommendation 1.2 adds new properties for the camera device use for recording a video and for referencing an item of a video planning system. All properties are shown at https://iptc.org/std/videometadatahub/recommendation/1.2
“Chasing the SmartPhoto” is the theme of the IPTC Photo Metadata Conference 2018. In the day-long conference, session speakers will examine the image business in a changing environment as new technologies, new devices and Artificial Intelligence will be game changers in the coming years. The Conference will be held in Berlin (Germany) on 31 May 2018. More details and how to register can be found at www.phmdc.org.
In the afternoon session titled “SmartPhotos and Smart Search Engines”, speakers from Google and Qwant will show how their search engines process photos found on the web and how they present search results. This session will include a discussion with conference participants about how photo businesses may critically perceive presentation of copyright protected photos.
”Protecting images Against Infringements” is the topic of another conference session. Publishing a photo on the Web opens up the possibility of anyone downloading and republishing it, without permission or paying for a license. Speakers from photo businesses and service providers will show how to implement copyright protection and how to track downloaded and reused photos using blockchain and other technologies.
The Photo Metadata Conference is organised by the International Press Telecommunications Council (IPTC, iptc.org), the body behind the industry standard for administrative, descriptive, and copyright information about images. It brings together photographers, photo editors, managers of metadata and system vendors to discuss how technical means can help improving the use of images. The Conference is held in conjunction with the annual CEPIC Congress (www.cepic.org).
The International Press Telecommunications Council (IPTC) has named Brendan Quinn as its new managing director.

Quinn joins the IPTC with two decades of experience in managing technology for media companies. In June 2018, he will succeed Michael Steidl, who will retire this summer after 15 years with the organisation. IPTC made the announcement today at their Spring Meeting in Athens.
Quinn brings to the IPTC a vast well of real-life experience in media industry technology, including leading the team that crafted the Associated Press’ APVideoHub.com video syndication platform, implementing content management systems at Fairfax Media in Australia, and handling an array of architecture and R&D roles over nine years with the BBC.
“I’m very much looking forward to my new role as MD for IPTC,” Quinn said. “I have huge respect for the organisation, in fact one of my first open source projects as a developer was writing a Perl module for NewsML v1 back in 2001 while I was a developer in Australia. I’m very proud to now be able to take the lead on defining the role of the IPTC in the challenging environment now faced by the media industry.”
Stuart Myles, Chairman of the Board of IPTC and Director of Information Management at the Associated Press, said he was “thrilled” to welcome Quinn to the organisation.
“He brings with him a wealth of news technology experience, with organisations from around the world and of all sizes. He has a unique combination of strategic insight into the challenges faced by the news industry and the technical know-how to help guide our work in technical standards and beyond.”
IPTC develops technical standards that address challenges in the news and photo industries, and other related fields. Recent IPTC initiatives are the Video Metadata Hub for mapping metadata across multiple existing standards; a major revision of RightsML for expressing machine readable licenses, now aligned with the new W3C standard ODRL; and a comprehensive update of SportsML for covering more efficiently a wide range of sports results and statistics. The Media Topics taxonomy for categorizing news now provides descriptions in four major languages.
Quinn says he looks forward to meeting IPTC members and learning as much as he can about the organization’s standards and outreach work.
“From iconic standards such as IPTC Photo Metadata and NewsML-G2 to emerging standards work like the Video Metadata Hub,” he said, “the IPTC aims to stay relevant in a changing media climate.”
About IPTC:
The IPTC, based in London, brings together the world’s leading news agencies, publishers, and industry vendors. It develops and promotes efficient technical standards to improve the management and exchange of information between content providers, intermediaries, and consumers. The standards enable easy, cost-effective, and rapid innovation and include the Photo Metadata and the Video Metadata Hub standards, the news exchange formats NewsML-G2, SportsML-G2 and NITF, rNews for marking up online news, the rights expression language RightsML, and NewsCodes taxonomies for categorizing news.
IPTC: www.iptc.org
Twitter: @IPTC
Brendan Quinn: @brendanquinn
Stuart Myles: @smyles
By Jennifer Parrucci
Senior Taxonomist at The New York Times
Lead of IPTC’s NewsCodes Working Group
The New York Times has a proud history of metadata. Every article published since The Times’s inception in 1851 contains descriptive metadata. The Times continues this tradition by incorporating metadata assignment into our publishing process today so that we can tag content in real-time and deliver key services to our readers and internal business clients.
I shared an overview of The Times’s tagging process at a recent conference held by the International Press Telecommunications Council in Barcelona. One of the purposes of IPTC’s face-to-face meetings is for members and prospective members to gain insight on how other member organizations categorize content, as well as handle new challenges as they relate to metadata in the news industry.
Why does The New York Times tag content today?
The Times doesn’t just tag content just for tradition’s sake. Tags play an important role in today’s newsroom. Tags are used to create collections of content and send out alerts on specific topics. In addition, tags help boost relevance on our site search and send a signal to external search engines, as well as inform content recommendations for readers. Tags are also used for tracking newsroom coverage, archive discovery, advertising and syndication.
How does The New York Times tag content?
The Times employs rules-based categorization, rather than purely statistical tagging or hand tagging, to assign metadata to all published content, including articles, videos, slideshows and interactive features.
Rules-based classification involves the use of software that parses customized rules that look at text and suggest tags based on how well they match the conditions of those rules. These rules might take into account things like the frequency of words or phrases in an asset, the position of words or phrases, for example whether a phrase appears in the headline or lead paragraph, a combination of words appearing in the same sentence, or a minimum amount of names or phrases associated with a subject appearing in an asset.
Unlike many other publications that use rules-based classification, The Times adds a layer of human supervision to tagging. While the software suggests the relevant subject terms and entities, the metadata is not assigned to the article until someone in the newsroom selects and assigns tags from that list of suggestions to an asset.
Why does The Times use rules-based and human supervised tagging?
This method of tagging allows for more transparency in rule writing to see why a rule has or has not matched. Additionally it gives the ability to customize rules based on patterns specific to our publication. For example, The Times has a specific style for obituaries, whereby the first sentence usually states someone died, followed by a short sentence stating his or her age. This language pattern can be included in the rule to increase the likelihood of obituaries matching with the term “Deaths (Obituaries).” Rules-based classification also allows for the creation of tags without needing to train a system. This option allows taxonomists to create rules for low-frequency topics and breaking news, for which sufficient content to train the system is lacking.
These rules can then be updated and modified as a topic or story changes and develops. Additionally, giving the newsroom rule suggestions and a controlled vocabulary to choose from ensures a greater consistency in tagging, while the human supervision of the tagging ensures quality.
What does the tagging process at The New York Times look like?
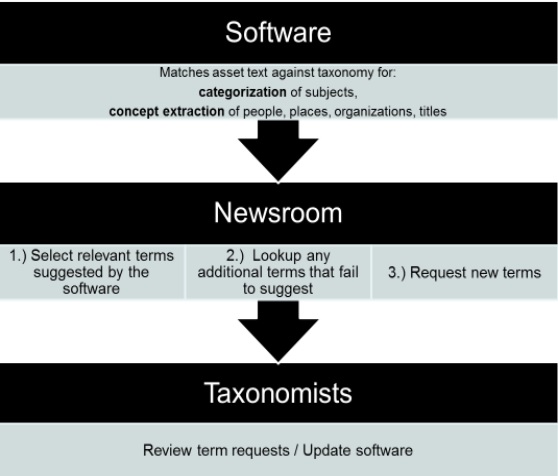
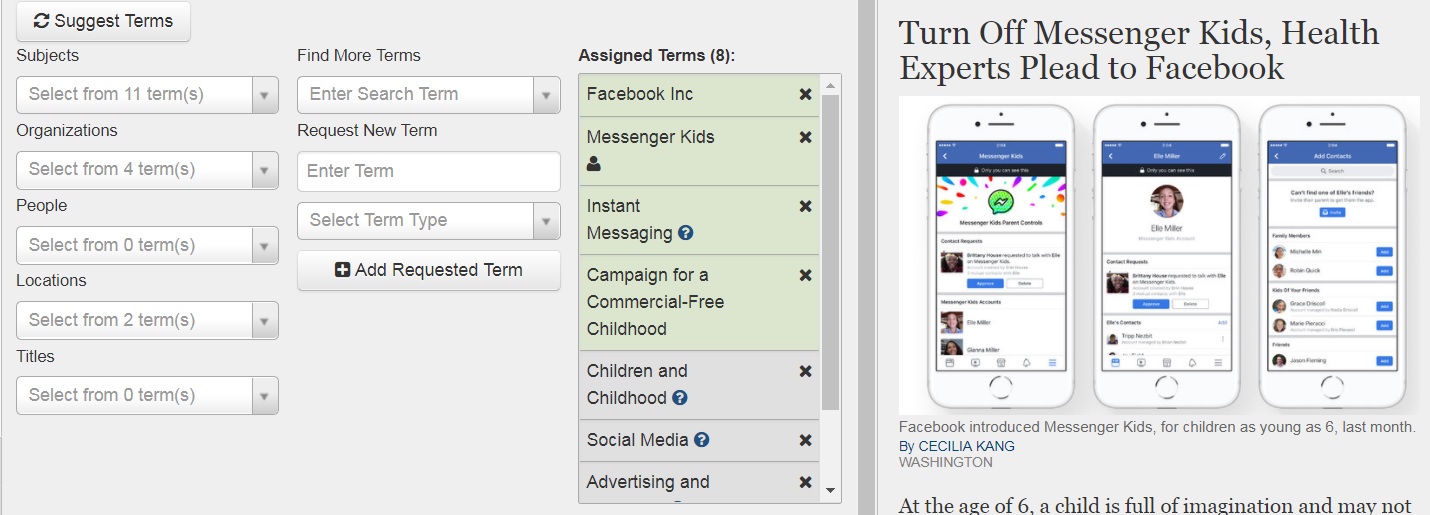
Once an asset (an article, slideshow, video or interactive feature) is created in the content management system, the categorization software is called. This software runs the text against the rules for subjects and then through the rules for entities (proper nouns). Once this process is complete, editors are presented with suggestions for each term type within our schema: subjects, organizations, people, locations and titles of creative works. The subject suggestions also contain a relevancy score. The editor can then choose tags from these suggestions to be assigned to an article. If they do not see a tag that they know is in the vocabulary suggested to them, the editors have the option to search for that term within the vocabulary. If there are new entities in the news, the editors can request that they be added as new terms. Once the article is published/republished the tags chosen from the vocabulary are assigned to the article and the requested terms are sent to the Taxonomy Team.
The Taxonomy Team receives all of the tag requests from the newsroom in a daily report. Taxonomists review the suggestions and decide whether they should be added to the vocabulary, taking into account factors such as: news value, frequency of occurrence, and uniqueness of the term. If the verdict is yes, then the taxonomist creates a new entry for the tag in our internal taxonomy management tool and disambiguates the entry using Boolean rules. For example, there cannot be two entries both named “Adams, John” for the composer and the former United States president of the same name. To solve this, disambiguation rules are added so that the software knows which one to suggest based on context.
John Adams,_IF:{(OR,”composer”,”Nixon in China”,”opera”…)}::Adams, John (1947- )
John Adams,_IF:{(OR,”federalist”,”Hamilton”,”David McCullough”…)}:Adams, John (1735-1826)
Once all of these new terms are added into the system, the Taxonomy Team retags all assets with the new terms.
In addition to these term updates, taxonomists also review a selection of assets from the day for tagging quality. Taxonomists read the articles to identify whether the asset has all the necessary tags or has been over-tagged. The general rule is to tag the focus of the article and not everything mentioned. This method ensures that the tagging really gets to the heart of what the piece is about. When doing this review, taxonomists will notice subject terms that are either not suggesting or suggesting improperly. The taxonomist uses this opportunity to tweak the rules for that subject so that the software suggests the tag properly next time.
After this review of the tagging process at the New York Times, the Taxonomy Team compiles a daily report back to the newsroom that includes shoutouts for good tagging examples, tips for future tagging and a list of all the new term updates for that day. This email keeps the newsroom and the Taxonomy Team in contact and acts as a continuous training tool for the newsroom.
All of these procedures come together to ensure that The Times has a high quality of metadata upon which to deliver highly relevant, targeted content to readers.
Read more about taxomony and IPTC standard Media Topics.