Categories
Archives

Following the recent announcements of Google’s signalling of generative AI content and Midjourney and Shutterstock the day after, Microsoft has now announced that it will also be signalling the provenance of content created by Microsoft’s generative AI tools such as Bing Image Creator.
Microsoft’s efforts go one step beyond those of Google and Midjourney, because they are adding the image metadata in a way that can be verified using digital certificates. This means that not only is the signal added to the image metadata, but verifiable information is added on who added the metadata and when.
As TechCrunch puts it, “Using cryptographic methods, the capabilities, scheduled to roll out in the coming months, will mark and sign AI-generated content with metadata about the origin of the image or video.”
The system uses the specification created by the Coalition for Content Provenance and Authenticity. a joint project of Project Origin and the Content Authenticity Initiative.
The 1.3 version of the C2PA Specification specifies how a C2PA Action can be used to signal provenance of Generative AI content. This uses the IPTC DigitalSourceType vocabulary – the same vocabulary used by the Google and Midjourney implementations.
This follows IPTC’s guidance on how to use the DigitalSourceType property, published earlier this month.

We have just finished the IPTC Spring Meeting in Tallinn, Estonia. Our first face-to-face IPTC Member Meeting since 2019, those who could attend in person were very happy to be back together, enabling collaboration, knowledge sharing and building bonds across organisations in the media industry.
We were also joined by over 50 online attendees from IPTC member organisations, who braved sometimes difficult timezone differences to view many of the sessions in real time and participate in discussions. Other IPTC members who weren’t able to be there either physically or virtually will be able to watch recordings of the sessions soon.
Themes this time obviously included Generative AI, but also fact-checking and provenance, social media embedding and social stories,
Highlights of the Monday included a special briefing about digital citizenship and digital governance at the e-Estonia Briefing Centre, where members heard from an Estonian government representative who described Estonia’s electronic tax, medicine, administration and even e-voting system, all powered by the cryptographically-protected digital ID card and the X-Road system of interconnecting all of e-Estonia’s services, across both the private and public sector.
Also on the Monday we heard from Gerd Kamp (dpa) who explained how dpa are using Web Components technology to embed social media into their articles in a way that’s much easier for their customers to process. We also heard Working Group presentations and new standard proposals from the NewsML-G2 Working Group and the News in JSON Working Group, whose lead Johan Lindgren (TT) handed over the reins to Ian Young (PA Media / Alamy) who promises to be a fine leader of the group in the future. We say many thanks to Johan for all his contributions to IPTC over the past 25 years!
We also heard from Evi Varsou (ATC) who demonstrated some of ATC’s tools for fighting fake news and misinformation, used by some of the world’s top news organisations.
Day 2 saw Dave Compton (Refinitiv, an LSE Group Company) describe some of their work on handling augmenting news content in real time with analytics information. Then we heard invited speaker Maria Amelie (Factiverse) talk about her troubles with the Norwegian authorities, being deported, and eventually getting Norwegian law changed to support refugees like herself. She now runs the startup Factiverse which is looking at using AI to help promote fact checks as fast as possible, via their site Factisearch (among other projects).
After a discussion on rights and RightsML, we heard from Estonian startup Texta (who provide several tools for media organisations, including an automated comment feed moderator that works in many languages), and German startup Storifyme.com who have created a tool that lets media companies quickly and easily create social posts from news stories – still very relevant even as Google AMP is being wound down.
Tuesday was rounded off by Jennifer Parrucci (The New York Times) presenting the NewsCodes Working Group‘s update, and Paul Kelly (Individual Member) giving an update on the huge amount of work on IPTC Sport Schema from the Sports Content Working Group.
On Wednesday, after an EGM voting on an update to the Articles of Association, we heard from Charlie Halford (BBC) on Project Origin and C2PA, and Sebastian Posth of International Standard Content Code.
We also voted in updates to NewsML-G2 and ninjs, which will be announced here soon.
We’re already looking forward to the Autuymn Meeting, held in October online, and Spring Meeting 2024, hopefully in New York City!

As a follow-up to yesterday’s news on Google using IPTC metadata to mark AI-generated content we are happy to announce that generative AI tools from Midjourney and Shutterstock will both be adopting the same guidelines.
According to a post on Google’s blog, Midjourney and Shutterstock will be using the same mechanism as Google – that is, using the IPTC “Digital Source Type” property to embed a marker that the content was created by a generative AI tool. Google will be detecting this metadata and using it to show a signal in search results that the content has been AI-generated.
A step towards implementing responsible practices for AI
We at IPTC are very excited to see this concrete implementation of our guidance on metadata for synthetic media.
We also see it as a real-world implementation of the guidelines on Responsible Practices for Synthetic Media from the Partnership on AI, and of the AI Ethical Guidelines for the Re-Use and Production of Visual Content from CEPIC, the alliance of European picture agencies. Both of these best practice guidelines emphasise the need for transparency in declaring content that was created using AI tools.
The phrase from the CEPIC transparency guidelines is “Inform users that the media or content is synthetic, through
labelling or cryptographic means, when the media created includes synthetic elements.”
The equivalent recommendation from the Partnership on AI guidelines is called indirect disclosure:
“Indirect disclosure is embedded and includes, but is not limited to, applying cryptographic provenance to synthetic outputs (such as the C2PA standard), applying traceable elements to training data and outputs, synthetic media file metadata, synthetic media pixel composition, and single-frame disclosure statements in videos”
Here is a simple, concrete way of implementing these disclosure / transparency guidelines using existing metadata standards.
Moving towards a provenance ecosystem
IPTC is also involved in efforts to embed transparency and provenance metadata in a way that can be protected using cryptography: C2PA, the Content Authenticity Initiative, and Project Origin.
C2PA provides a way of declaring the same “Digital Source Type” information in a more robust way, that can provide mechanisms to retrieve metadata even after the image was manipulated or after the metadata was stripped from the file.
However implementing C2PA technology is more complicated, and involves obtaining and managing digital certificates, among other things. Also C2PA technology has not been implemented by platforms or search engines on the display side.
In the short term, AI content creation systems can use this simple mechanism to add disclosure information to their content.
The IPTC is happy to help any other parties to implement these metadata signals: please contact IPTC via the Contact Us form.
At today’s Google I/O event keynote, Sundar Pichai, CEO of Google, explained how Google will be using embedded IPTC image metadata to signal visual media created by generative AI models.
“Moving forward, we are building our models to include watermarking and other techniques from the start,” Pichai said. “If you look at a synthetic image, it’s impressive how real it looks, so you can imagine how important this is going to be in the future.
“Metadata allows content creators to associate additional context with original files, giving you more information whenever you encounter an image. We’ll ensure every one of our AI-generated images has that metadata.”
The IPTC Photo Metadata section of Google Images’ guidance on metadata has been updated with new guidance on the DigitalSourceType field:
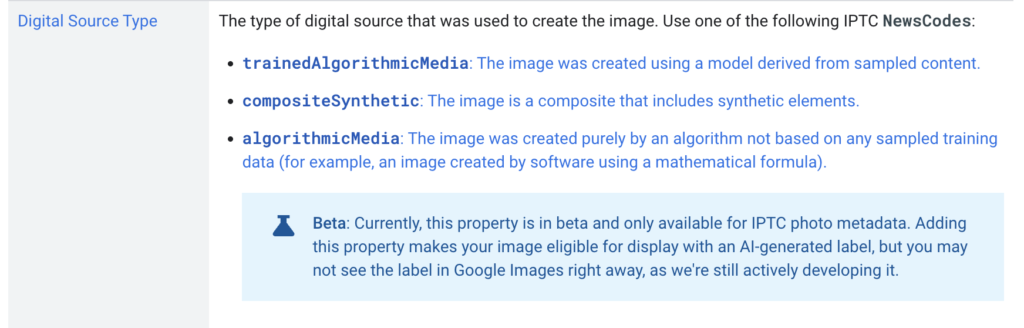
This follows the guidance on IPTC Photo Metadata for Generative AI that was recently published by IPTC.
“AI-Generated” label on Google Images
The above guidance hints at an “AI-generated label” to be used on Google Images in the future. Google recommends that all creators of AI-generated images use the IPTC Digital Source Type property to signal AI-generated content. While Google says that “you may not see the label in Google Images right away”, it appears that it will soon be available in Google Images search results.

The IPTC has updated its Photo Metadata User Guide to include some best practice guidelines for how to use embedded metadata to signal “synthetic media” content that was created by generative AI systems.
After our work in 2022 and the draft vocabulary to support synthetic media, the IPTC NewsCodes Working Group, Video Metadata Working Group and Photo Metadata Working Group worked together with several experts and organisations to come up with a definitive list of “digital source types” that includes various types of machine-generated content, or hybrid human and machine-generated media.
Since publishing the vocabulary, the work has been picked up by the Coalition for Content Provenance and Authenticity (C2PA) via the use of digitalSourceType in Actions and in the IPTC Photo and Video Metadata assertion. But the primary use case is for adding metadata to image and video files
Here is a direct link to the new section on Guidance for using Digital Source Type, including examples for how the various terms can be used to describe media created in different formats – audio, video, images and even text.
IPTC recommends that software creating images using trained AI algorithms uses the “Digital Source Type” value of “trainedAlgorithmicMedia” is added to the XMP data packet in generated image and video files. Alternatively, it may be included in a C2PA manifest as described in the IPTC assertion documentation in the C2PA specification.
The official URL for the full vocabulary is http://cv.iptc.org/newscodes/digitalsourcetype, so the complete URI for the recommended Trained Algorithmic Media term is http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia.
Other terms in the vocabulary include:
- Composite with synthetic elements – https://cv.iptc.org/newscodes/digitalsourcetype/compositeSynthetic – covering a composite image that contains some synthetic and some elements captured with a camera;
- Digital Art – https://cv.iptc.org/newscodes/digitalsourcetype/digitalArt – covering art created by a human using digital tools such as a mouse or digital pencil, or computer-generated imagery (CGI) video
- Virtual recording – https://cv.iptc.org/newscodes/digitalsourcetype/virtualRecording – a recording of a virtual event which may or may not contain synthetic elements, such as a Fortnite game or a Zoom meeting
- and several other options – see the full list with examples in the IPTC Photo Metadata User Guide.
Of course, the original digital source type values covering photographs taken on a digital camera or phone (digitalCapture), scan from negative (negativeFilm), and images digitised from print (print) are also valid and may continue to be used. We have, however, retired the generic term “softwareImage” which is now deemed to be too generic. We recommend using one of the newer terms in its place.
If you are considering implementing this guidance in AI image generation software, we would love to hear about it so we can offer advice and tell others. Please contact us using the IPTC contact form.
 Today, IPTC announces the biggest change to the NewsCodes vocabularies in years. Almost 200 terms have been modified in the Media Topics vocabulary, including many “retirements”, trimming the CV down to exactly 1100 terms.
Today, IPTC announces the biggest change to the NewsCodes vocabularies in years. Almost 200 terms have been modified in the Media Topics vocabulary, including many “retirements”, trimming the CV down to exactly 1100 terms.
Overall, three controlled vocabularies have been updated: Content Warning, Content Production Party Role and Media Topic.
The changes to Media Topic CV are the biggest ever, with 9 new concepts, 60 retired concepts and 120 modified concepts, including 79 hierarchy moves.
The NewsCodes Working Group has been working hard on this update for over six months, bringing much-needed clarity to the “economy, business and finance” branch.
As part of the review, the “economic sector” sub-branch has been re-named “products and services”, handle both the companies making products or providing services, and also the products and services themselves.
Specifically, we have changed the following:
- 9 New concepts: business reporting and performance, business restructuring, commercial real estate, residential real estate, podcast, financial service, business service, news industry and diversity, equity and inclusion.
- 60 retired concepts: business finance, accounting and audit, analysts comment, earnings forecast, stock option, licensing agreement, aquaculture, arable farming, livestock farming, viniculture, fertiliser, health and beauty product, inorganic chemical, organic chemical, computer networking, computer security, telecommunication equipment, design and engineering, house building, land price, real estate, beverage, grocery, mail order, non-durable good, kerosene/paraffin, financial and business service, funeral parlour and crematorium, janitorial service, personal finance, personal income, personal service, printing service, wedding service, industrial component, instrument engineering, news agency, newspaper and magazine, online media industry, iron and steel, mining, non-ferrous metal, process industry, distiller and brewer, paper and packaging product, rubber product, soft drinks, textile and clothing, traffic, securities, renewable energy, stock recommendation, buy recommendation, hold recommendation, sell recommendation, hot stock, Internet of Things, capital goods, e-cigarette and commercial building. Most of these have notes attached describing which terms should be used instead of the retired ones.
- 39 name (label) changes: terrorist bombings, stock buyback corporate dividends corporate earnings, business financing, shareholder activity, executive officer, business strategy and marketing, products and services, commercial fishing, plastic, computer and telecommunications hardware, semiconductor and electronic component, software and applications, restoration, online shopping, toy and game, renewable energy, electricity, waste management, auction, consultancy, financial advisory service, personal finance and investment, shipping and postal service, media and entertainment industry, books and publishing, film industry, metal and mineral mining and refining, precious material, beverage and grocery, tobacco and nicotine, casinos and gambling, derivatives, stocks and securities, handicrafts, oil and gas, sales channel and heating and cooling.
- 81 definition changes: cyber crime, war crime, bankruptcy, stock buyback, corporate dividends, corporate earnings, business financing, shareholder activity, stock option, business governance, new product or service, patent, copyright and trademark, products and services, agriculture, commercial fishing, forestry and timber, pharmaceutical, plastic, computing and information technology, computer and telecommunications hardware, semiconductor and electronic component, software and applications, telecommunication service, wireless technology, restoration, clothing, online shopping, luxury good, retail, toy and game, energy and resource, renewable energy, diesel fuel, electricity, natural gas, waste management, water supply, accountancy and auditing, auction, banking, market research, personal finance and investment, rental service, shipping and postal service, defence equipment, heavy engineering, machine manufacturing, shipbuilding, media and entertainment industry, advertising, books and publishing, film industry, music industry, public relations, radio industry, television industry, metal and mineral mining and refining, building material, precious material, beverage and grocery, tobacco and nicotine, tourism and leisure industry, casinos and gambling, hotel and accommodation, restaurant and catering, tour operator, transport, air transport, railway transport, road transport, derivatives, stocks and securities, handicrafts, asset management, railway manufacturing, medical equipment, pet product and service, biofuel, utilities, streaming service and crowdfunding.
Currently, the name and description changes have only been made in English (both en-GB and en-US variants). Other language versions will come soon when their maintainers can make the appropriate changes to their translations.
Changes to Content Warning CV
New terms Drug Use, Fantasy Violence, Flashing Lights, Personally Identifiable Information to match standard terms used in the industry. The “Flashing Lights” term is intended to be used for flagging content that may trigger photosensitive epilepsy, a key accessibility concern by many broadcasters and a legal requirement in some countries.
Label change: Suffering to Upsetting and Disturbing to match industry usage.
Changes to Content Production Party Role CV
New term Distributor. Changed definition of Information Originator.
More information on IPTC Controlled Vocabularies
As always, the Media Topics vocabularies can be viewed in the following ways:
- In a collapsible tree view
- As a downloadable Excel spreadsheet
- On one page on the cv.iptc.org server
- In machine readable formats such as RDF/XML and Turtle using the SKOS vocabulary format. See the cv.iptc.org guidelines document for more detail.
For more information on IPTC NewsCodes in general, please see the IPTC NewsCodes Guidelines.

The IPTC is very happy to announce that it has joined the Steering Committee of Project Origin, one of the industry’s key initiatives to fight misinformation online through the use of tamper-evident metadata embedded in media files.
After working with Project Origin over a number of years, and co-hosting a series of workshops during 2022, the organisation formally invited the IPTC to join the Steering Committee.
Current Steering Committee members are Microsoft, the BBC and CBC / Radio Canada. The New York Times also participates in Steering Committee meetings through its Research & Development department.
“We were very happy to co-host with Project Origin a productive series of webinars and workshops during 2022, introducing the details of C2PA technology to the news and media industry and discussing the remaining issues to drive wider adoption,” says Brendan Quinn, Managing Director of the IPTC.
C2PA, the Coalition for Content Provenance and Authenticity, took a set of requirements from both Project Origin and the Content Authenticity Initiative to create a technical means of associating media files with information on the origin and subsequent modifications of news stories and other media content.
“Project Origin’s aim is to take the ground-breaking technical specification created by C2PA and make it realistic and relevant for newsrooms around the world,” Quinn said. “This is very much in keeping with the IPTC’s mission to help media organisations to succeed by sharing best practices, creating open standards and facilitating collaboration between media and technology organisations.”
“The IPTC is a perfect partner for Project Origin as we work to connect newsrooms through secure metadata,” said Bruce MacCormack, the CBC/Radio-Canada Co-Lead.
The announcement was made at the Trusted News Initiative event held in London today, 30 March 2023, where representatives of the BBC, AFP, Microsoft, Meta and many others gathered to discuss trust, misinformation and authenticity in news media.
Learn more about Project Origin by contacting us or viewing the video below:

IPTC Managing Director Brendan Quinn presented at the European Broadcasting Union’s Data Technology Seminar last week.
The DataTech Seminar, known in previous years as the Metadata Developers Network, brought over 100 technologists together in person in Geneva to discuss topics related to managing data at broadcasters in Europe and around the world.
Brendan spoke on Tuesday 21st March on a panel discussing Artificial Intelligence and the Media. Brendan used the opportunity to discuss IPTC’s current work on “do not train” signals in metadata, and on establishing best practices for how AI tools can embed metadata indicating the origin of their media.
The work of C2PA, Project Origin and Content Authenticity Initiative on addressing content provenance and tamper-evident media was also highlighted by Brendan during the panel discussion, as this relates to the prevalence of “deepfake” content that can be created by generative AI engines.
On Wednesday 22nd March, Brendan spoke in lieu of Paul Kelly, lead of the IPTC Sports Content Working Group about the IPTC SportSchema project. The session was called “IPTC Sport Schema – the next generation of sports data.” An evolution of IPTC’s SportsML standard, IPTC Sport Schema brings our 20 years of experience in sports data markup to the world of Knowledge Graphs and the Semantic Web. The specification is coming close to a version 1, so we were very proud to present it to some of the world’s top broadcasters and industry players.
The IPTC SportSchema site sportschema.org now includes comprehensive documentation of the ontology behind sports data model, examples of how it can be queried using SPARQL, example data files and instance diagrams showing how it can be used to represent common sports such as athletics, soccer, golf and hockey.
We look forward to discussing IPTC Sport Schema much more over the coming months, as we draw close to its general release.
EBU members can watch the full presentation at the EBU.ch site.
Our friends at CEPIC are running a webinar in conjunction with Google on the Licensable badge in search results. The webinar is TODAY, February 21st, so there are still a few hours left to join.
Register for free at https://www.eventbrite.com/e/google-webinar-image-seo-and-licensable-badge-tickets-532031278877
Google webinar: Image SEO and Licensable Badge
In this webinar, John Mueller, Google’s Search Advocate, will cover Image SEO Best Practices and Google’s Licensable Badge. For the Licensable Badge, John will give an overview of the product and implementation guidelines. There will also be time for a Q&A session.
One of the methods for enabling your licensing metadata to be surfaced in Google Search results is to embed the correct IPTC Photo Metadata directly into image files. The other is to use schema.org markup in the page hosting the image. We explain more in the Quick Guide to IPTC Photo Metadata on Google Images, but you can also learn about it by attending this webinar.
Tuesday 21st February 2023, at 4 PM – 5PM Central European Time
Topics covered include:
• Image SEO best practices
• Licensable badge in Google image search results
• Q&A
This is a free webinar open to all those interested, not just CEPIC or IPTC members.
The IPTC has long worked with organisations on schemas for representing news and media content in all of their forms.
Back in early 2022, the IPTC started hosting the BBC Ontologies, a set of semantic web vocabularies created between 2012 and 2014 that can be used to describe news content, sports, TV and radio programmes and more. When the BBC stopped hosting them in late 2021, IPTC offered to host them on the BBC’s behalf.
“I’m very grateful to the IPTC for providing hosting for these ontologies while we perform some maintenance on their former home,” said Jeremy Tarling, Head of Content Metadata for the BBC, at the time. “For those BBC ontologies relevant to IPTC’s mission we would be keen to discuss longer-term arrangements for their hosting and ownership.”
Since then we have added the SNaP Ontology, a similar semantic web ontology created by the UK’s national news agency PA Media (known at the time as the Press Association). The SNaP ontology was similarly left without a home after the PA brand change.
“We are delighted for the SNaP Ontologies to find their home with the IPTC and its community,” said Steve Robinson, Director of Technology, PA Media Group. “It is our hope that these ontologies, complemented by other member contributions, will support the IPTC’s continued evolution of digital news standards.”
While neither of these standards are being actively developed, we at the IPTC think that they should be accessible to researchers, architects and developers in the future who may want to draw upon their concepts and vocabularies.
In fact, the BBC Sport Ontology is being used as one of the sources of inspiration for IPTC’s forthcoming sports data ontology, which will be announced soon.
With that in mind, the IPTC is willing to host other data schemas and specifications, especially those that are no longer hosted by their creators. If you have suggestions for resources that we should host in our third party area, please let us know.